Scales beyond.
Scales beyond.
Grows with you, from startup to industry icon
Grows with you, from startup to industry icon

Never overpay
for unused infra
Never overpay
for unused infra
Mage doesn’t just process data, it revolutionizes how you think about scalability by intelligently scaling data pipelines, vertically and horizontally, in real-time while maintaining peak performance and reducing costs by up to 40%.
Mage doesn’t just process data, it revolutionizes how you think about scalability by intelligently scaling data pipelines, vertically and horizontally, in real-time while maintaining peak performance and reducing costs by up to 40%.
Dynamic blocks
True dynamos!
True dynamos!
Mage’s hyper-concurrency engine splits workloads into independent and self-managing units. These tasks are dynamically generated and distributed across your infrastructure, maximizing speed and processing power across all available resources.
Mage’s hyper-concurrency engine splits workloads into independent and self-managing units. These tasks are dynamically generated and distributed across your infrastructure, maximizing speed and processing power across all available resources.
Dynamic blocks adapt their behavior based on input data or runtime conditions, enabling the creation of flexible and complex data pipelines that can easily accommodate varying scalability requirements all without the need to write duplicate code.
Dynamic blocks revolutionize pipeline architecture through adaptive parallelism and context-aware execution, transforming static code from rigid sequences into living neural networks of data processing.
Dynamic blocks revolutionize pipeline architecture through adaptive parallelism and context-aware execution, transforming static code from rigid sequences into living neural networks of data processing.
Try it yourself
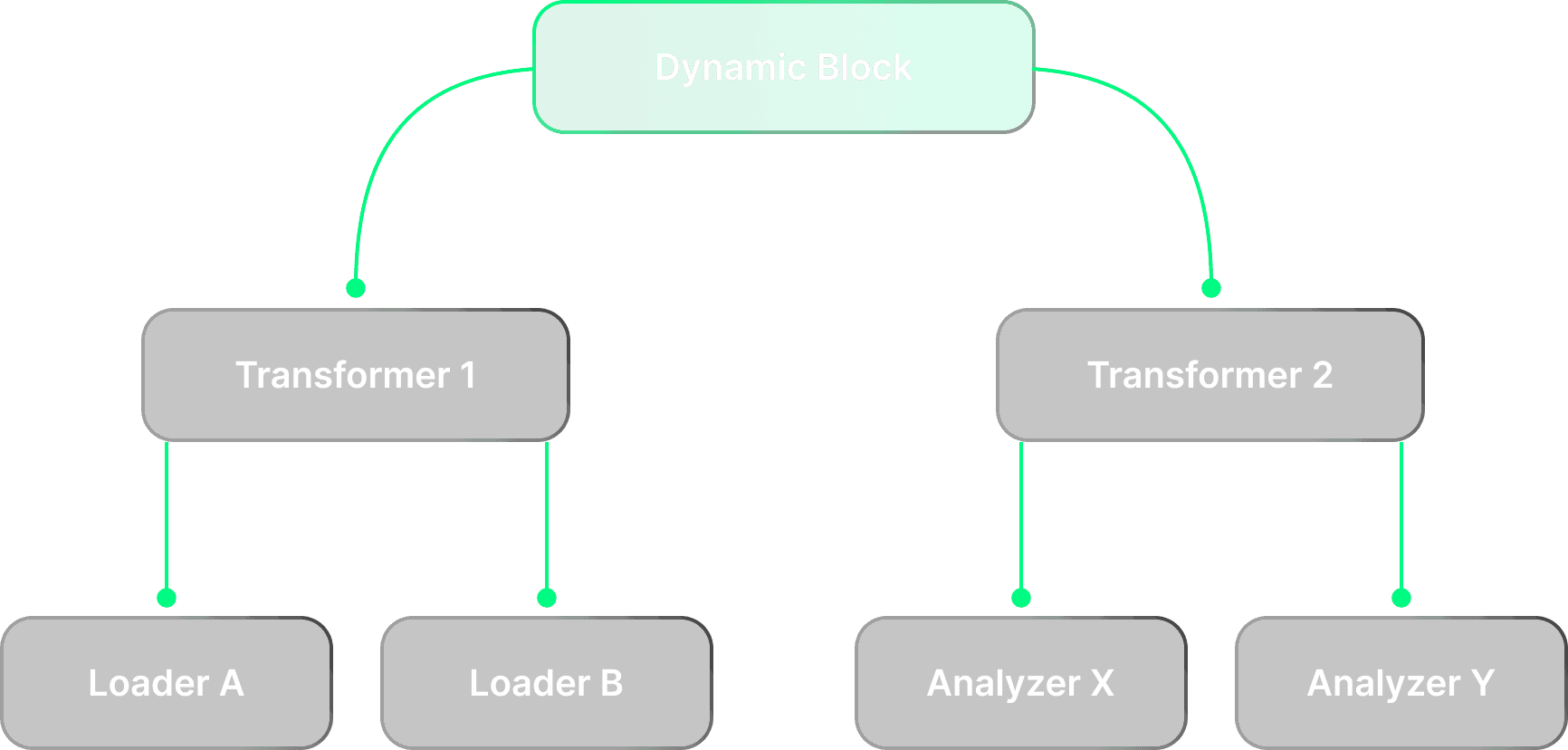
Unlike static DAGs, dynamic blocks enable fractal-like processing trees that auto-scale with data complexity. This represents a paradigm shift in data pipeline orchestration, enabling intelligent workload distribution and runtime flexibility that sets the platform apart from traditional ETL tools.
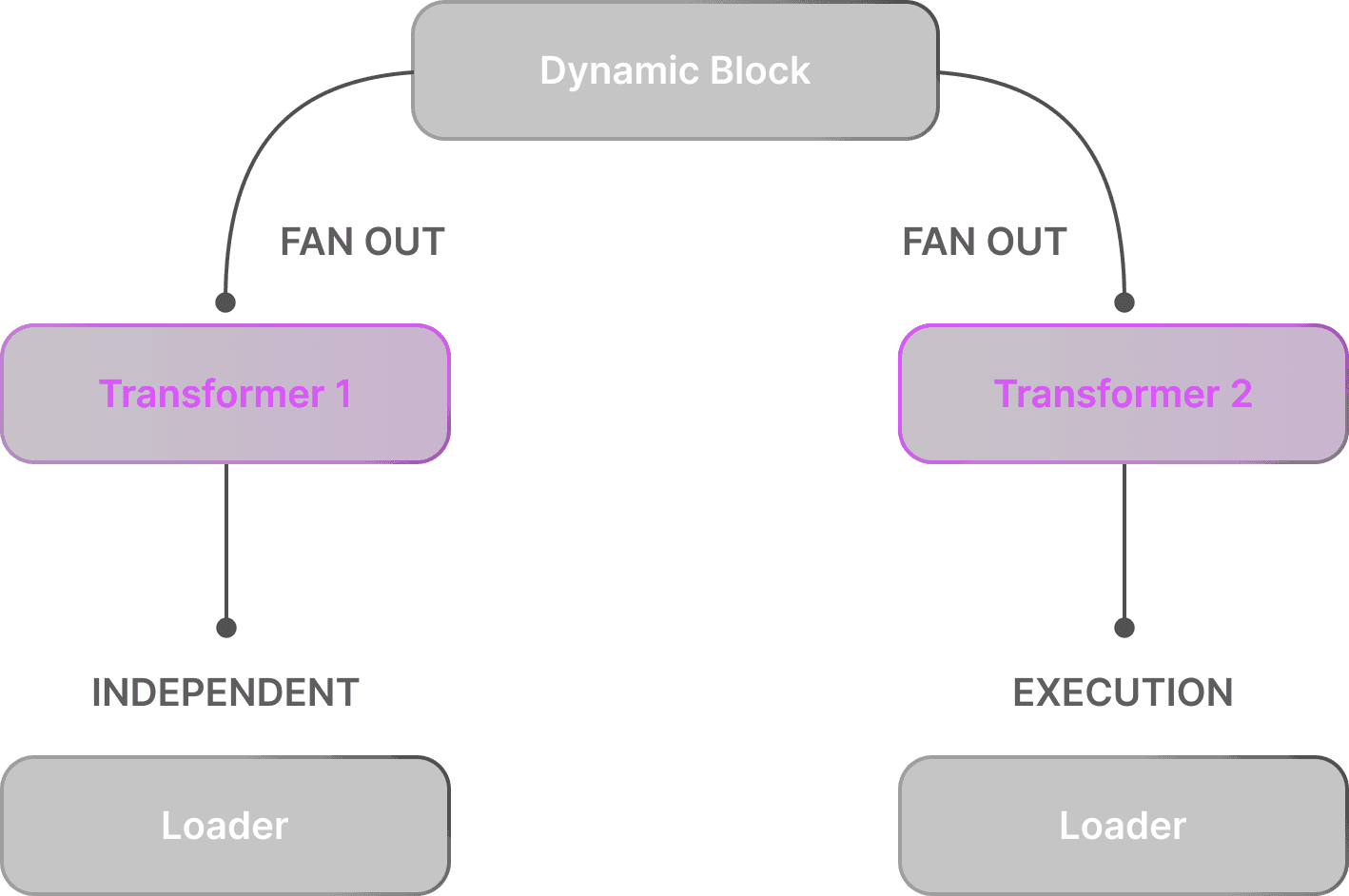
Asynchronous Execution Matrix
Asynchronous Execution Matrix
Sibling blocks execute concurrently without synchronization
Sibling blocks execute concurrently without synchronization
Each branch maintains isolated context through UUID-bound metadata
Each branch maintains isolated context through UUID-bound metadata
Failure domains constrained to individual data partitions and doesn’t affect the sibling branches
Failure domains constrained to individual data partitions and doesn’t affect the sibling branches

Stream mode execution
Stream mode execution
Continuous data hydration enables processing records before the full dataset lands
Continuous data hydration enables processing records before the full dataset lands
Achieve 60% faster data delivery SLAs
Achieve 60% faster data delivery SLAs
90% memory reduction vs batch processing
90% memory reduction vs batch processing
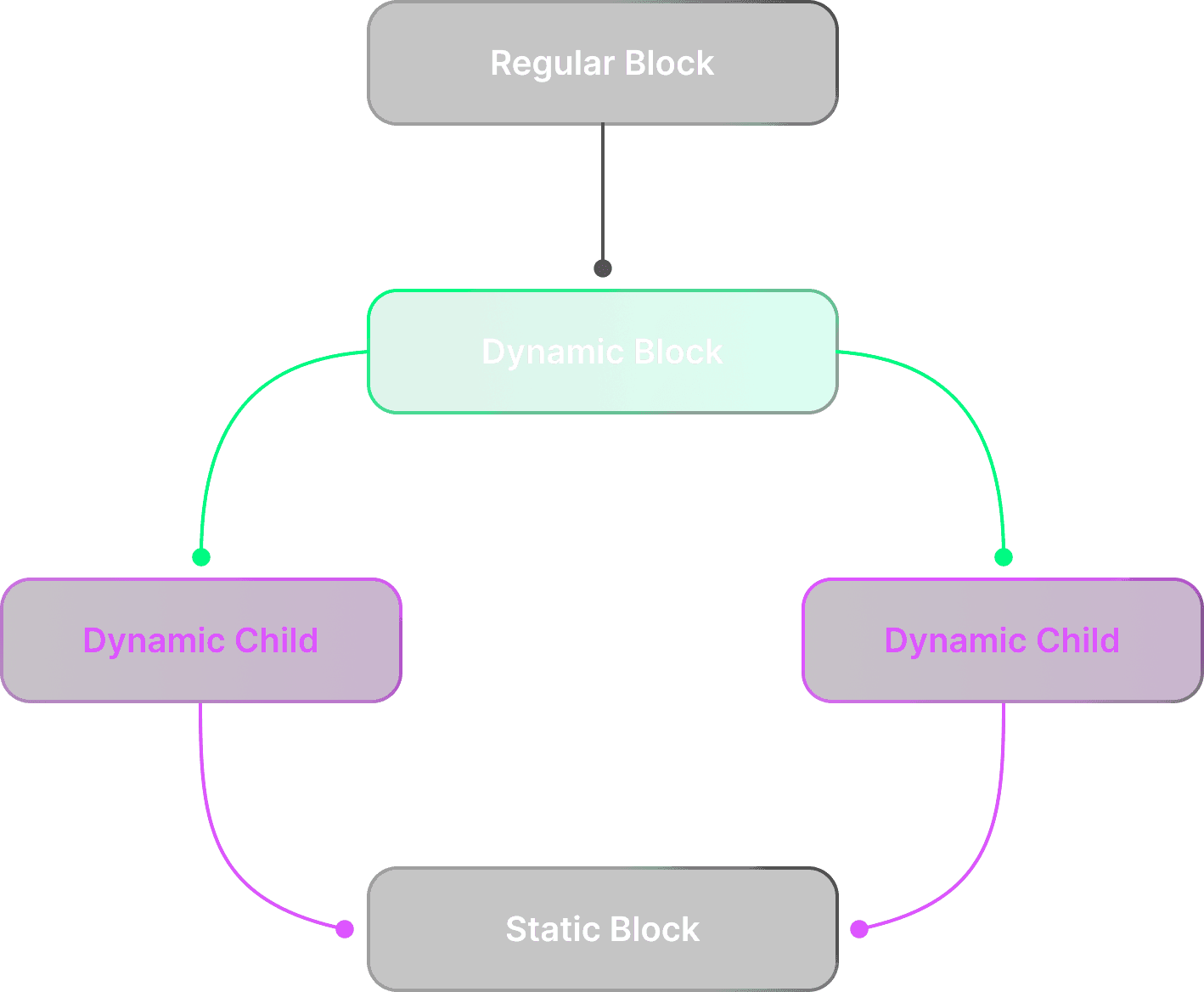
Adaptive topology support
Adaptive topology support
Hybrid parentage: Combine static/dynamic upstreams
Hybrid parentage: Combine static/dynamic upstreams
Multi-parent orchestration through metadata inheritance
Multi-parent orchestration through metadata inheritance
Auto-generated UUIDs prevent namespace collisions
Auto-generated UUIDs prevent namespace collisions
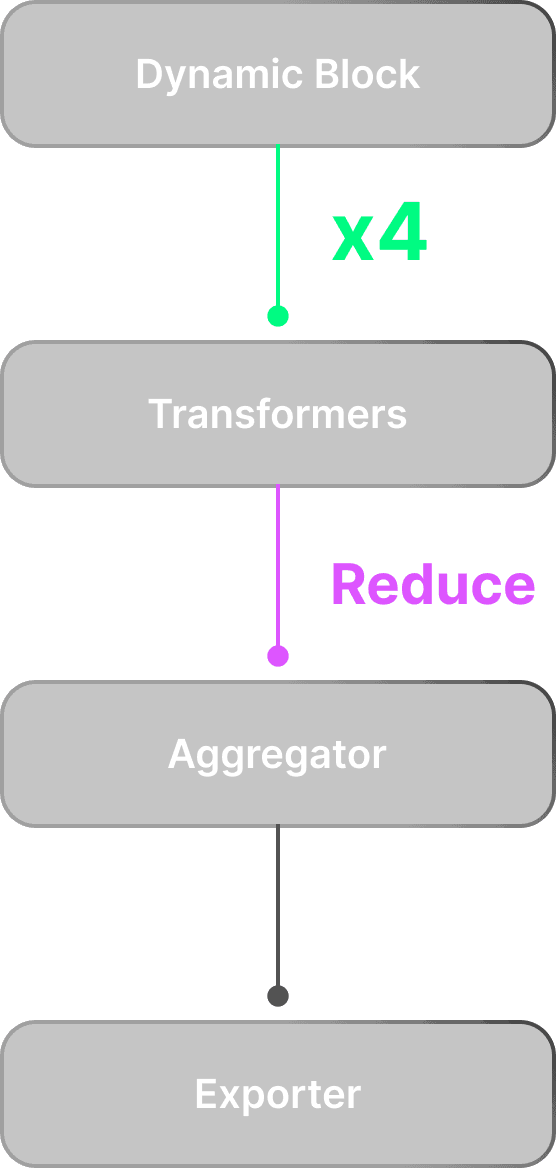
Recursive reduction engine
Recursive reduction engine
Fan-in patterns to reduce each block’s data output into a single source of data
Fan-in patterns to reduce each block’s data output into a single source of data
Multiple reduction strategies (concat, sum, merge)
Multiple reduction strategies (concat, sum, merge)
Preserved data lineage through reduction stages
Preserved data lineage through reduction stages
Spark
Spark magic in lightning time
Spark magic in lightning time
Run PySpark and SparkSQL alongside vanilla Python – zero infra tax, maximum data power. Mage AI provides a robust interface for monitoring and debugging your Spark pipelines, offering detailed insights into execution metrics, stages, and SQL operations.
Run PySpark and SparkSQL alongside vanilla Python – zero infra tax, maximum data power. Mage AI provides a robust interface for monitoring and debugging your Spark pipelines, offering detailed insights into execution metrics, stages, and SQL operations.
Infrastructure autopilot. Mage auto-provisions optimized clusters on-demand per data pipeline needs.
Infrastructure autopilot. Mage auto-provisions optimized clusters on-demand per data pipeline needs.
Try it yourself
Execution metrics overview. Track Spark execution metrics during development and in production.
Execution metrics overview. Track Spark execution metrics during development and in production.
Try it yourself
Code hybridization engine. Seamless context handoff between Spark, Pandas, Polars, PyArrow, and other Python objects.
Code hybridization engine. Seamless context handoff between Spark, Pandas, Polars, PyArrow, and other Python objects.
Stages and tasks analysis. See what is happening along the way.
Stages and tasks analysis. See what is happening along the way.
Try it yourself
Visualize task execution phases (e.g., shuffle read/write, deserialization) to identify bottlenecks.
Visualize task execution phases (e.g., shuffle read/write, deserialization) to identify bottlenecks.
Analyze key metrics such as input records, shuffle bytes, and GC time to optimize performance.
Drill into individual tasks to debug failures or inefficiencies.
SQL execution insights. Gain a deeper understanding of your Spark queries
SQL execution insights. Gain a deeper understanding of your Spark queries
Try it yourself

View the query plan as a graph to understand how Spark processes data (e.g., scans, transformations).
Inspect detailed statistics like scan time, file sizes, and output rows for each stage of the query.
Track SQL statements across multiple jobs with completion status and durations.
Integrations
Build anything,
connect to everything
Build anything,
connect to everything







All your favorites. From zero-copy Polars to petabyte-scale Iceberg – wield without infra tax.
All your favorites. From zero-copy Polars to petabyte-scale Iceberg – wield without infra tax.
Avoid vendor lock in. Blend cloud SQL engines with OSS formats.
Avoid vendor lock in. Blend cloud SQL engines with OSS formats.
Cost arbitrage. Process cold data in DuckDB / Polars and hot data in BigQuery / Snowflake.
Cost arbitrage. Process cold data in DuckDB / Polars and hot data in BigQuery / Snowflake.

Big data, small cost
Mage AI’s smart resource management…
Automatically matches processing power to workload demands
Automatically matches processing power to workload demands
Eliminates wasted capacity with predictive scaling
Eliminates wasted capacity with predictive scaling
Processes massive datasets without costly hardware upgrades
Processes massive datasets without costly hardware upgrades
Reduces cloud spend while maintaining petabyte-scale throughput
Reduces cloud spend while maintaining petabyte-scale throughput
Recover your precious developer time
Now you can focus on the fun, creative, and high-impact data engineering projects and let Mage AI handle the rest.
For engineers
Experience how Mage AI ships data pipelines faster, giving you a better work-life-balance.
For data teams
See how Mage AI accelerates your team velocity while reducing data and infrastructure costs.






Recover your precious developer time
Now you can focus on the fun, creative, and high-impact data engineering projects and let Mage AI handle the rest.
For engineers
Experience how Mage AI ships data pipelines faster, giving you a better work-life-balance.
For data teams
See how Mage AI accelerates your team velocity while reducing data and infrastructure costs.
Product
Solutions
Made in Silicon Valley © 2026
Product
Solutions
Made in Silicon Valley © 2026